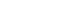

予告先発より先を予想する -機械学習の手法を用いて-
日本のプロ野球ではセ・リーグ、パ・リーグ共に予告先発制度が採用されています。そのため、翌日の試合で誰が先発登板するのか一目瞭然で分かります。それでは、翌々日の先発投手は誰でしょうか? はたまた3日後、4日後、・・・、7日後の先発投手は誰でしょうか? そういった翌日だけではなく、数日後の先発投手を予想することはできないのでしょうか。今回は機械学習の手法を用いて、7試合分の先発投手を予想してみようと思います。
最終的な予想結果とは
まず初めに、最終的にどのような結果を得るのかイメージできると内容を理解しやすいと思います。ですので、最終的な結果の一部を先にご覧ください。
上図のように、ある基準日からの7試合分の先発投手を予想しました。同様のことを2015年の開幕戦から最終戦まで、12球団全てに対して行っていきました。それでは次節から、どのようなデータを用いて、どのような方法で予想していったのかを順を追って説明します。
予想に使用するデータおよび方法
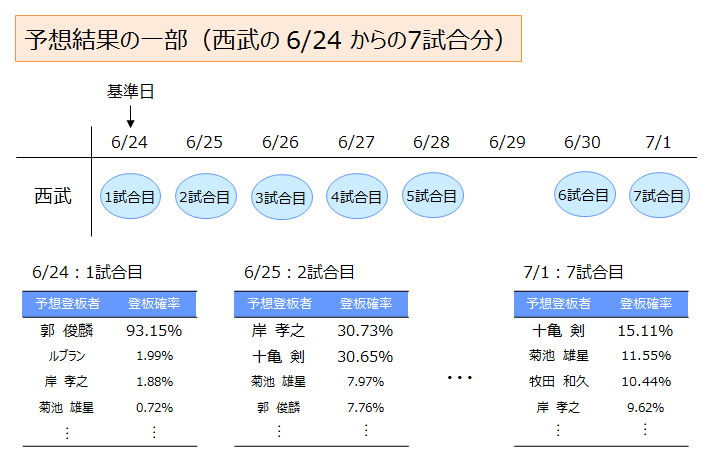
まず、予想に用いたデータについてです。先発投手を決めるときにどのような要因が効いてくるのかを考えた上でデータを準備します。例えば、登板間隔について考えてみると、登板間隔1日の投手と登板間隔6日の投手を比較した際、明らかに後者の投手を先発させるはずです。よって登板間隔のデータは重要であると推測できます。他にも、翌日に誰が先発するのか(予告先発情報)、投手の力量を表す1軍・2軍の基本成績(防御率、投球回数など)、去年の1軍・2軍の基本成績、対戦相手との相性(X球団に対する防御率、ゲーム差など)、予想する時期を表す情報(試合消化率)、そもそも今季どれだけ先発登板しているのか(今季先発登板数)、などが重要そうであると推測できます。このようにして、予想に必要なデータを準備していきました。これらデータを「選手に関するデータ」と「チームに関するデータ」の2つに大きく分け、概略図にまとめました。
次に、予想の方法についてです。今回はランダムフォレストと呼ばれる機械学習(データを基にある規則性を見つけ出すこと)の手法を用いました。詳細な説明は行いませんが、「ある変数がある条件を満たすかどうか」を何度か調べていった結果、ある選手の登板確率を求めることができるという手法です。厳密性を省いたイメージ図を載せますので、こちらで説明します。イメージ図の左下に2択でどんどん分岐していく構造があると思います。この2択で分岐する際に、登板間隔が6日以上かどうか、先発登板数が5回以上かどうか、などで分岐していきます。その結果、行き着いた先によって各選手の登板確率が求まっていくというイメージです。このようにして登板確率を求めていくにあたって、どの変数で分岐すると有効であるのか、分岐の境界となる値はいくつが良いのかは簡単には判断が付きません。そこで、それらを統計的に計算して求めたものが今回のランダムフォレストとなっています。

ここまでの内容を一旦まとめておきます。今回は、12球団の7試合分の先発投手を予想することを目的としています。「選手データ」と「チームデータ」を基にランダムフォレストと呼ばれる手法を用いて、先発投手の登板確率を求めました。以上の手順を経て、本コラム冒頭に掲載したような予想結果を開幕戦から最終戦まで得ました。最後に、予想結果を少し詳しく見ていきましょう。
予想結果を眺めてみる
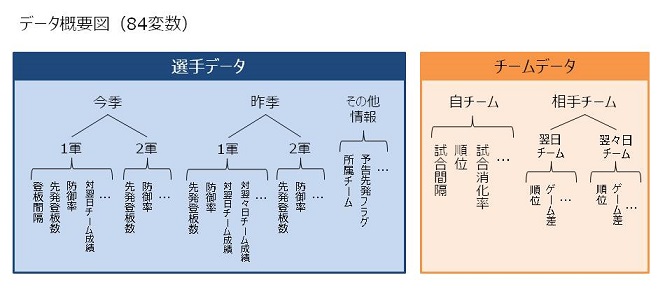
ここでは、2015年8月24日を基準日とした、ソフトバンクに焦点を当てます。なお、各試合の登板確率上位5名のみを載せています。
1試合目は予告先発が出ているので、約95%という高い確率で寺原隼人の先発が予想されているのが分かります。2試合目以降は、登板確率最大の選手であっても20〜40%台の登板確率となっています。その影響で、3試合目や5試合目のように登板確率上位2名に大きな差がなく、どちらが先発してもおかしくない時もあります。類似して、日付の近い試合において登板確率上位2名(今回は2試合目と3試合目)の予想登板者と実際登板者が逆になる場合もあります。また、実際に登板した選手と登板確率最大の選手が一致した場合を予想的中とすると、7試合中4試合で予想的中でした。
以上のように、7試合分の先発投手の予想を行ってみました。予想結果を見てもらうと分かるように、予想が外れることもありますが、ある程度の精度で予想可能であると分かります。しかし、今回は述べていませんが、シーズン中のデータがほとんどないシーズン序盤、日程的に余裕が生まれる交流戦期間、前年度データのない新加入選手に対する予想精度が低くなってしまう課題もあります。
現在、随時検証を行いながらこれら課題を修正している段階です。先発投手を予想してみようという試みを、いずれBaseball LAB上で皆さんに提供できればと考えています。本コラムを機に多くの方に興味を持っていただければ幸いです。